
使用MoSCoW法则排定Sprint Backlog的优先级
- 2022-09-09 13:41:40
- 小船哥说敏捷
- 转贴:
- 微信公众号
- 8312
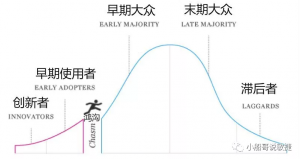
我们在敏捷开发中一直强调要将Backlog按优先级排序,迭代的时候也严格按照这个优先级来开发,这样就可以保证我们当下是在交付最高价值的用户故事(User Story,以下简称US)了,就像下图这样,最高优先级的故事最先被完成:
那我们应该怎样对Sprint Backlog进行排序,才能让高优先级的故事最先被完成呢?本文将介绍一个优先级排序工具:MoSCoW法则,来帮助大家对Sprint Backlog做出一份合理的优先级排序。
1. 什么是MoSCoW法则
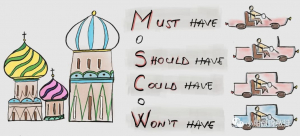
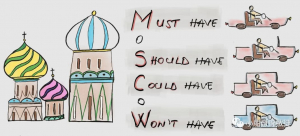
1.1. MoSCoW中的四个大写字母
MoSCoW的四个大写字母,M、S、C、W分别对应以下四个词汇的首字母:
- Must have:必须有。
- Should have:应该有。
- Could have:可能有。
- Won’t have(this time):(这次)不会有。
1.2. MoSCoW中的两个小写字母
其实莫斯科法则的全称是:
Must or Should, Could or Won't.
为什么Must和Should中间有一个or,Could和Won't中间也有一个or,而Should和Could中间却没有?是不是老外为了读起来有朗朗上口的感觉,特地这么设计的?
其实不是的,真实原因是因为要区分一个US是Should have还是Could have是很容易的,但是要区分一个US是Must have还是Should have,或者是Could have还是Won't have的时候,不同的人会有不同的看法,即使是同一个人,不同时间、不同环境下看同一个US,也可能会得出不一样的结论。这段描述是不是看得有点头晕?没关系,举个例子你应该就明白了:
- 作为一个电商APP的用户,我想注册一个账号,以便可以买到我心仪的商品。(以下简称注册账号)
- 作为一个电商APP的用户,我想编辑我的个人资料,以便可以个性化我的个人信息。(以下简称编辑资料)
如果从Should have还是Could have的角度来划分以上2个US,你们会得出怎样的判断?
我在公司组织过一个10人的小组投票,结果如下:
投票结果几乎是一边倒,注册账号是应该做的(Should have),编辑资料是可以做的(Could have)。
- 注册账号是必须做的(Must have),还是应该做的(Should have)?
- 编辑资料是可能做的(Could have),还是可能不做的(Won't have)?
然后大家就吵起来了。
- 甲:没有注册功能,我怎么知道是哪个用户下的单呢?所以我觉得是Must have。
- 乙:干嘛非要有个注册功能呢?用户可以用三方账号授权登录啊,比如微信或微博授权登录不就可以了吗?所以我觉得注册功能不是Must have,应该是Should have。
- 甲:登录功能强依赖第三方APP,会被App Store拒绝上架的。
- 乙:那可以接入苹果账号的授权登录啊!
- 甲:那Android和网页版怎么办呢?
- 乙:那可以用微信授权登录啊!
- 甲:那工作量岂不是比开发一个注册功能还要大!
- ……
同样,编辑资料这个US也是各有各的理解,但是谁也不能说服对方。
求同存异
一个US,只要确定它是Must or Should还是Could or Won't,而不用细化到Must、Should、Could还是Won't。
这里插个题外话,之前一个咨询公司的副总在给我们最敏捷导入培训的时候,谈起敏捷宣言的诞生过程,他说了这么一个小故事(不知道真假,大家看看就好):
当年那17位敏捷大师在犹他州的滑雪场聚会的时候,他们一开始是想定一个大家都认可的实践方案的(比如类似Scrum、Kanban、XP等),但是发现分歧实在太大了,每个人都认为自己的实践方案是最优的,后来大家实在谈不下去了,于是就退而求其次,大家发现每种实践方案的指导思想基本都是一致的,所以就抽象出了一份《敏捷宣言》。
2. Sprint Backlog优先级的确定
2.1. PO使用MoSCoW法则对Sprint Backlog排定优先级
在对Product Backlog的高优先级的故事进行梳理和估算之后,PO需要在Sprint计划会之前再对这份潜在的Sprint Backlog做一次优先级的排序,排序的原则就是MoSCoW法则。PO在实际使用这个法则的时候,其实不需要刻板的拿Must or Should还是Could or Won't这个概念往上套,而是问自己这么一个问题:
这个US如果本次Sprint做不完,我(以及我所代表的利益相关者)可以接受吗?
如果可以接受,那就把这个US放到Could or Won't,否则就放到Must or Should。
至此,PO对优先级排序的主要工作就结束了,但是,这样就算完成了吗?
2.2. 开发团队对Sprint Backlog排定优先级
此时PO已经使用MoSCoW法则对Sprint Backlog做了优先级的排序,但是这个排序是PO是从“必须做完”和“可以做不完”的角度给的(准确的说,只能算是个分类),大部分情况下,研发团队并不能严格按照这个顺序来开发,举个常见的例子:
我们研发的大部分的功能模块,可能都会涉及“增删改查”的功能,做过开发的同学都知道,这几个功能的研发顺序,一般都是遵从增→查→删/改的顺序来进行的,不做增,是没法查的;不做查,是没法删/改的(手动操作数据库除外)。
因为大部分PO不懂技术,所以他/她可能会把增/查放到“可以做不完”的分类中,而把删/改放到“必须做完”的分类中;或者把删/改的优先级放到增/查前面,这就导致如果按照这个优先级的排序来开发,会导致研发的同学进行不下去的。
这里再插个题外话:
程序员跟产品经理经常互怼,本质上是因为这两个群体的思维方式完全不一样:
在拿到一个需求之后,技术思维想的是:这个需求好实现么? 实现起来需要多长时间?这样操作会不会有性能问题,以前的代码支持这个功能可能需要重构,那我们赶紧团结起来,把这个需求怼回去。
总之一句话,技术思维多是以自我为中心的,而产品思维是以用户为中心的。这一点导致在Backlog优先级的划分上,两边也会存在分歧。而Sprint计划会,正是解决这个分歧的最佳时机,而促成解决这个分歧的人,就是SM。
- 实现依赖
- 团队依赖
- 技能依赖
- 其他
有一点请注意:
研发团队的排序前提,是在PO给定的2个大的分类范围内进行的,原则上只能将低优先级的故事提到高优先级上(从“可以做不完”提升到“必须做完”),如果要将一个“必须做完”的故事降低到“可以做不完”,需要征得PO的同意。
至此,Sprint Backlog的优先级排序工作全部完成。
3. 一些特殊情况的补充说明
每个敏捷团队的人员组成都是不一样的,技能也是不一样的,做的事情也是不一样的,所以上面的方法可能也不是适用于每个团队,但是有些特殊情况,还是有些应对方式的。
3.1. 项目要求和研发技能不匹配
这是我们经常遇到的一个问题,就是我们要做的事情,可能以我们团队目前的人员配置,并不是最合适的,比如我们团队有2个很厉害的APP研发,但是我们要做的项目并没有APP的任务,那怎么办呢?
我的做法是鼓励大家再学习一门新的知识,在一个氛围良好、沟通顺畅、充满心理安全感的团队中,团队成员是不排斥、也不惧怕学习新知识的。
那一个研发人员,需要学习多长时间才能上手一门新技术呢?
- 所有的学习任务,都要当做“学习型”US,放到Sprint Backlog中,并且设置明确的验收标准(AC),比如:
- 作为研发人员,我想看完《XXX从入门到放弃》,以便掌握XXX的基础知识。
- 作为研发人员,我想使用X编程语言模仿Y做一个Y demo,以便促进我更好的掌握X的知识。
- 学习型US,也一样贴到Scrum板,每日站会的时候跟踪进度。以我个人的经验,即使是学习一项全新的知识,2个迭代(4周)基本也就能上手了。
3.2. 每个迭代开始前,都要重新评估Poduct Backlog中所有US的优先级
我在文章开始的时候举了个例子:
作为一个电商APP的用户,我想编辑我的个人资料,以便可以个性化我的个人信息。(以下简称编辑资料)
这个US大部分人都选了Could or Won't的优先级,也就是这条是“可以做不完”的,但是我们可以看下淘宝、京东等主流的电商APP,他们都是有编辑资料这个功能的,而且功能做得还都特别完善。那为什么我当时调研的人大都选择了“可以做不完”,而淘宝、京东他们却不约而同的都做了个这么尽善尽美的编辑资料功能呢?难道是我们的判断标准跟他们不一致?
其实不是判断标准不一样,而是编辑资料这个功能对于一个刚起步的电商软件和一个成熟的电商软件的价值不一样:
假设电商APP的用户中有1%的人想要用这个功能,那在项目早期,可能日活(DAU)也就几十、上百人,即使发展到成千上万人,可能也不会影响到多少用户。但是如果我们项目的DAU达到十万、数十万甚至百万级别了,那影响到的用户可能就要达到几千甚至上万人了,到了这个时候,编辑资料这个US的价值就大大提升了,如果到那时这个需求还没有做,PO就要在合适的时间点,将这个US挪到“必须做完”这个级别了。
3.3. 其他
由于每个人的从事的工作不同、所在的团队不同、团队成员的水平也不同,所以可能还有一些个性化的情况没有谈到,大家如果有问题,可以留言一起讨论下。
最后希望大家带领的每个团队都能有一个完美的迭代过程!






- 联系人:阿道
- 联系方式: 17762006160
- 地址:青岛市黄岛区长江西路118号青铁广场18楼
如果您有优秀的原创文章,欢迎添加联系人直接与我们联系,或通过下方邮箱发送投稿文章,一经采用,我们会付以一定的稿件报酬。
- 投稿邮箱: yanruiyu@easycorp.ltd
- 投稿标题:向 [敏捷开发] 网站投稿
- 稿件要求:与敏捷开发相关的任何内容
更多投稿相关请点击 更多进行了解~
